SLA Tier III+ en colocation datacenter IA : que doit garantir votre contrat ?
Un SLA de colocation datacenter IA n’est pas un label de communication. C’est un document contractuel qui définit ce que l’opérateur vous doit, et ce qu’il paie s’il ne le tient pas. Pour un engagement de 6 à 9 ans sur 6 à 7 MW IT de workloads d’inférence IA, la différence entre un SLA bien rédigé et un SLA de façade se mesure au moment où votre infrastructure tombe, pas avant. Cet article détaille ce qu’un contrat de colocation IA doit contenir pour être défendable devant vos achats, votre CFO et votre board, et pourquoi la plupart des SLA du marché ne passent pas ce test.
TL;DR Un label Tier III+ ne suffit pas, seul le contrat protège vraiment votre infrastructure. Un SLA défendable définit la disponibilité composant par composant, couvre la redondance N+1 sur les circuits DLC, prévoit des pénalités réelles y compris sur le refroidissement, et contractualise le MTTR. Sur un engagement de 6 à 9 ans, la solidité de l’exploitant (EQUANS) compte autant que les clauses.
Ce que Tier III+ change vraiment dans votre contrat
La certification Tier III+ de l’Uptime Institute est une référence technique reconnue. Elle ne suffit pas à protéger votre infrastructure si les engagements qu’elle implique ne sont pas traduits en clauses contractuelles opposables. Le label certifie la conception et la construction. Le contrat, lui, engage l’opérateur sur l’exploitation réelle. C’est là que se joue votre risque.
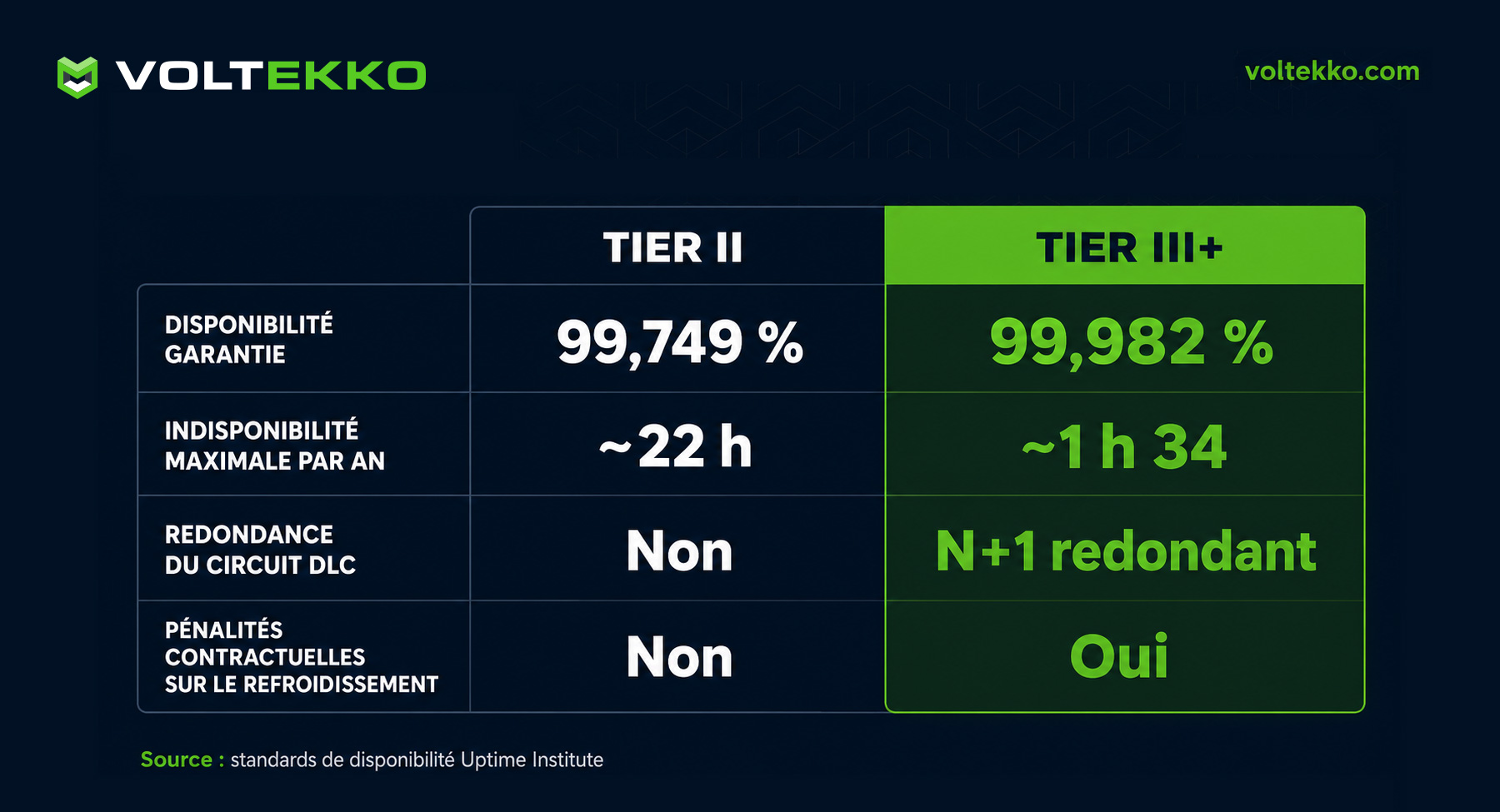
Disponibilité 99,982% : le calcul que votre contrat doit rendre opposable
La disponibilité Tier III+ se traduit par 99,982% de temps de fonctionnement garanti, soit un maximum de 1h34 d’indisponibilité cumulée par an. Ce chiffre ne vaut que s’il est défini par composant critique dans votre contrat, pas globalement.
Un SLA global à 99,9% peut masquer une alimentation à 99,5% et un réseau à 99,95%. Sur 6 MW IT d’inférence GPU, une alimentation à 99,5% représente 43h d’indisponibilité potentielle par an. À l’échelle d’un parc GPU de cette taille, où chaque heure d’arrêt immobilise un actif dont l’amortissement continue de courir, l’écart entre un SLA précis et un SLA global se chiffre vite en exposition annuelle significative.
Ce que votre contrat doit contenir : une définition de la disponibilité par système (alimentation, refroidissement DLC, réseau), avec un reporting mensuel automatique et des valeurs seuils opposables. Si l’opérateur refuse cette granularité, le SLA global est une déclaration d’intention.
| Métrique | Tier II | Tier III | Tier III+ |
|---|---|---|---|
| Disponibilité garantie | 99,749% | 99,982% | 99,982% + maintenance sans interruption |
| Indisponibilité max/an | ~22h | ~1h34 | ~1h34 (maintenance en ligne incluse) |
| Redondance alimentation | Partielle | N+1 | N+1 concurrent |
| Redondance refroidissement | Non | N+1 | N+1 concurrent + circuit DLC redondant |
| Maintenance sans coupure | Non | Non | Oui |
| Certification Uptime Institute | Non obligatoire | Tier III | Tier III+ Design + Constructed Facility |
Redondance N+1 : ce que ça signifie pour vos workloads GPU
La redondance N+1 signifie que chaque système critique dispose d’une unité de secours inactive, prête à prendre le relais sans intervention humaine. Sur l’alimentation et le réseau, ce mécanisme est bien documenté dans les standards du secteur. Sur le refroidissement liquide DLC, il est moins souvent traité avec la précision qu’il mérite.
Un rack GPU à 100 kW en DLC natif génère un débit thermique que l’air cooling ne peut pas absorber en secours. Si votre contrat garantit la redondance N+1 sur l’alimentation mais reste silencieux sur les circuits DLC, vous avez un angle mort critique. En cas de défaillance d’un circuit de refroidissement liquide, le basculement sur air cooling n’est pas possible à cette densité. Vos GPU s’éteignent en protection thermique dans les minutes qui suivent.
Ce que votre contrat doit préciser : redondance N+1 explicitement couverte sur les circuits DLC primaires et secondaires, avec basculement automatique testé et documenté. La fréquence des tests de basculement (trimestrielle au minimum) doit être inscrite dans le contrat, pas dans une annexe technique révisable unilatéralement.
Les clauses que la plupart des contrats omettent
Les pénalités financières réelles : le test de sincérité de l’opérateur
Un SLA sans pénalité financière définie est une déclaration d’intention. Ce point est non négociable pour un engagement pluriannuel sur des workloads critiques.
La structure de pénalité à exiger : un crédit de service calculé sur la durée d’indisponibilité effective, avec des paliers progressifs. Un exemple de structure défendable : 10% du loyer mensuel par heure d’indisponibilité au-delà du SLA, plafonné à 30% du loyer mensuel sur la période. Ces chiffres ne sont pas des standards universels, ils sont négociables, mais leur existence dans le contrat est le signal que l’opérateur accepte d’être tenu responsable de ses engagements.
Deux points d’attention souvent omis dans la négociation. Premier point : les pénalités doivent s’appliquer aux incidents de refroidissement au même titre qu’aux coupures d’alimentation. Dans un datacenter DLC haute densité, un incident de refroidissement est aussi critique qu’une coupure d’alimentation, et les SLA du marché l’excluent fréquemment. Second point : la définition de l’indisponibilité doit être précisée. Une dégradation de performance qui maintient vos GPU en fonctionnement à 60% de leur capacité nominale est-elle couverte ? Si votre contrat ne le précise pas, la réponse est non.
Le MTTR contractualisé : combien de temps pour rétablir un système critique ?
Le MTTR (Mean Time To Repair) est le délai maximum de rétablissement d’un système après incident. Il doit être contractuellement défini, pas laissé à l’appréciation de l’opérateur.
Les standards de marché actuels : 4 heures pour un incident alimentation, 2 heures pour un incident réseau. Ces valeurs sont négociables à la baisse si l’exploitant dispose d’une astreinte permanente et d’un stock de pièces critiques sur site. Pour des workloads d’inférence GPU à haute densité, une indisponibilité de 2 heures sur 6 MW IT représente une perte directe et calculable. Intégrez ce chiffre dans votre négociation du MTTR, pas comme argument émotionnel mais comme base de calcul des pénalités.
C’est précisément sur ce point qu’EQUANS, filiale Bouygues et exploitant opérationnel des infrastructures Voltekko, apporte une garantie que peu d’opérateurs peuvent formuler. Avec 20 ans d’exploitation de datacenters et une équipe d’astreinte permanente 24/7/365, EQUANS porte la responsabilité opérationnelle du MTTR sur toute la durée de l’engagement client. Ce n’est pas une promesse de startup. C’est l’engagement d’un exploitant industriel dont la continuité ne dépend pas d’un prochain tour de financement.
Les blocs de capacité dédiés : l’engagement qui protège votre planification
La différence entre colocation mutualisée et bloc dédié est fondamentale pour un neocloud IA en scaling. Un bloc de 6 à 7 MW IT dédié signifie que votre puissance IT n’est pas partagée, que votre alimentation est dimensionnée exclusivement pour vos besoins, et que votre capacité de scaling est contractuellement préservée sur la durée de l’engagement.
Ce que votre contrat doit préciser sur ce point : la puissance IT garantie par bloc (en kW, pas en équivalent rack), la possibilité d’extension avec un délai de notification défini (90 jours est un standard acceptable), et les conditions de révision de capacité à la hausse sans renégociation de l’intégralité du contrat.
Pour votre board, cet argument est concret : un bloc dédié élimine le risque de contention de ressources. Chez un opérateur mutualisé en période de forte demande GPU, votre accès à la puissance IT peut être dégradé sans violation formelle du SLA, dès lors que ce SLA ne garantit pas l’exclusivité de votre bloc. Ce risque n’est pas théorique. La demande de capacité GPU en Europe a connu une croissance brutale depuis 2023, et les opérateurs mutualisés sont sous forte pression capacitaire.
Pourquoi l’exploitant compte autant que le contrat
Un bon contrat avec un exploitant défaillant ne vaut rien à 3h du matin quand un circuit DLC tombe. La qualité de l’exploitant opérationnel est la variable que la plupart des dossiers de sélection sous-pondèrent, jusqu’au premier incident.
EQUANS : 20 ans d’exploitation datacenter, pas un sous-traitant de construction
EQUANS est souvent présenté comme le partenaire de construction et de conception des infrastructures Voltekko. C’est exact, mais c’est la partie visible. La partie qui compte pour votre engagement à 9 ans, c’est l’exploitation.
EQUANS, filiale de Bouygues, est l’exploitant opérationnel contractuellement engagé sur les sites Voltekko, en France (région parisienne) et au Portugal (Alcochete, en construction). Cela signifie concrètement : astreinte permanente 24/7/365, maintenance préventive industrialisée selon des process éprouvés sur 20 ans d’exploitation datacenter, chaîne de responsabilité claire en cas d’incident, et processus d’escalade définis contractuellement, pas laissés à la discrétion d’une équipe technique dont la composition peut changer.
La question que votre board posera inévitablement : « Qui opère dans 7 ans, à 3h du matin, quand un système critique tombe ? » La réponse est EQUANS. Pas une équipe de cinq ingénieurs recrutés il y a 18 mois. Un exploitant industriel de premier rang dont la continuité opérationnelle est structurellement garantie par son appartenance au groupe Bouygues.
La structure de responsabilité : qui répond de quoi ?
La clarté de la chaîne de responsabilité est un critère de sélection que vos achats vont examiner. Voici comment elle se structure chez Voltekko.
Voltekko est l’opérateur et l’interlocuteur contractuel unique du client. C’est Voltekko qui signe le contrat de colocation, qui porte les engagements SLA, et qui est l’interlocuteur de premier niveau pour toute question contractuelle ou commerciale.
EQUANS est l’exploitant opérationnel, responsable de la tenue des SLA techniques sur l’alimentation, le refroidissement DLC et le réseau. La responsabilité opérationnelle est portée par un acteur industriel dont la surface financière et la continuité ne dépendent pas de la trajectoire de financement de Voltekko.
REED, filiale du groupe Société Générale, est l’investisseur institutionnel au capital de Voltekko. La présence de REED n’est pas un argument de communication. C’est une structure de risque que votre board peut analyser. Un opérateur adossé à la Société Générale dispose d’une crédibilité financière que vos achats peuvent vérifier, et d’une pérennité que les opérateurs indépendants sans ancrage institutionnel ne peuvent pas offrir.
Cette structure à trois niveaux (opérateur contractuel, exploitant industriel, investisseur institutionnel) est précisément ce qui permet de répondre à l’objection la plus fréquente dans les comités de décision : « Et si l’opérateur n’existe plus dans 5 ans ? »
SLA colocation datacenter IA : les points à verrouiller avant de signer
Un SLA Tier III+ n’est défendable devant votre board que s’il contient cinq éléments précis : une disponibilité définie par composant critique (pas globalement), une redondance N+1 explicitement couverte sur les circuits DLC, des pénalités financières progressives applicables à tous les systèmes critiques, un MTTR contractualisé par type d’incident, et une définition de la capacité dédiée en puissance IT garantie.
Si votre contrat de colocation actuel ou en cours de négociation ne contient pas ces cinq éléments, vous portez un risque opérationnel que votre board n’a pas validé, parce qu’il ne lui a pas été présenté sous cette forme.
Sur le même sujet
- DLC natif et PUE 1.2 : optimiser le TCO de votre inférence IA
- Au-delà du Tier IV : garantir la résilience de vos infrastructures critiques
- Refroidissement liquide : la rupture nécessaire face à la haute densité
Vous évaluez un contrat de colocation pour vos workloads d’inférence IA ?